One of the most common questions I hear when discussing AI and analytics is:
“Why can’t I just point an LLM at my SQL database and get answers?”
At first glance, this seems reasonable. If large language models can write SQL, why not let them query the database directly? For simple questions such as:
“How many customers do I have?”
A single LLM may perform well because the answer likely lives in a single table, and the SQL is straightforward. However, a more enterprise-type question might look something like this:
“How many customers do I have in each state in the United States who have made more than five purchases?”
Now, the AI model suddenly has to:
- Understand multiple domain concepts
- Evaluate relationships across several tables
- Perform joins, grouping, filtering, and conditional aggregation
- Retrieve domain knowledge that possibly exists outside of the database and table schemas
In other words, the model must reason across semantics, context, and enterprise specific logic, all without hallucinating and this is where LLMs can break down. To better understand this challenge and approaches for how to design architectures to solve this, let’s examine a recent study “Text-to-SQL for Enterprise Data Analytics”, conducted by Chen et al. (2025).
Why Single LLMs are Not Enough
Chen et al. (2025), start their research by asking a fair question:
“Do we even need agents? Or can a single LLM solve this?”
It turns out single LLMs struggle heavily when it comes to complex enterprise data structures as seen when we come the Spider 1.0 and Spider 2.0 benchmarks. You can also check out the most current rankings here.
| Benchmark | Test Criteria | Single LM Accuracy |
| Spider 1.0 | Simple, academic | GPT-4 90% |
| Spider 2.0 | True enterprise complexity | GPT-4 drops to 13%, o1 and o3 scored slightly better in the 20-30% range |
| Snowflake Internal Eval | Real enterprise data | ~51% (GPT-4o) |
These benchmark results confirm a key point that enterprise text to SQL truly requires multi-stage, agentic workflows.
Key Architectural Components
To overcome this limitation, Chen et al. (2025) propose and evaluate agentic design principles that can bridge these performance gaps.
A Comprehensive Enterprise Knowledge Graph
First, the researchers designed and implemented a knowledge graph. A knowledge graph is crucial for helping the LLM reason about semantics and the knowledge graph designed in the study was built around the following integrations:
- Table schema metadata
- Documentation, business definitions, and organization jargon (such as abbreviations, metrics names, products, team names, etc.
- Historical SQL queries
- Code repositories
The graph, shown in Figure 1, is designed to provide the LLM with contextual understanding of how data is used, what tables mean, and how various systems relate, something a standalone model cannot infer.
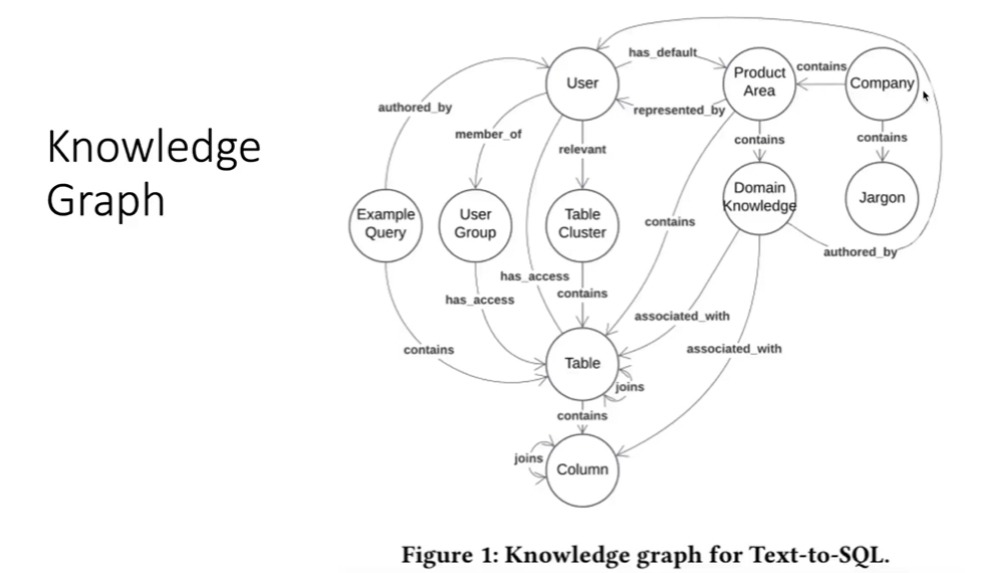
Chen et al. (2025) Figure 1. Text-to-SQL for Enterprise Data Analytics. https://arxiv.org/abs/2507.14372
Table Clustering
In an enterprise, we may have thousands if not millions of tables, but not all are relevant for every user query. Chen et al. (2025), explain that by clustering data, we can help Ai Agents interpret enterprise data with greater accuracy because this process helps remove noise and low-relevance context which can lead to hallucinations. The clustering process used in the study includes the following key steps:
- Preparing user access data
- Evaluate the datasets for user access counts and which users are access the datasets
- Filtering and scaling out the data
- Reduce noise and only include datasets with sufficient number of total and unique user access and remove rarely used tables
- Perform Dimensionality Reduction (ICA) and apply Independent Component Analysis to score each table and component
In their study, Chen et al. (2025) found that without data clustering, accuracy was as low as 9% compared to an accuracy rate of 48% with clustering. These results validate how essential clustering is for enterprise RAG and agentic SQL workflows.
Multi-Stage Retrieval and Query-Writing Agent
Lastly, rather than feeding the model everything, the team discussed their approach to building a multi-stage process that:
- Retrieves all potentially relevant tables
- Ranks them
- Selects a top subset
- Enriches context using the knowledge graph
- Passes only the highest-quality context into the Query Writer Agent
- Generates SQL query
- Validates and refines the output
Using this approach the team was able to dramatically boost the relevance and accuracy of the responses. We can see this workflow in Figure 2, and the query writer agent has four main steps, retrieving the context, ranking, writing the query, and fixing the query. This process can loop multiple times based on any errors or hallucinations.
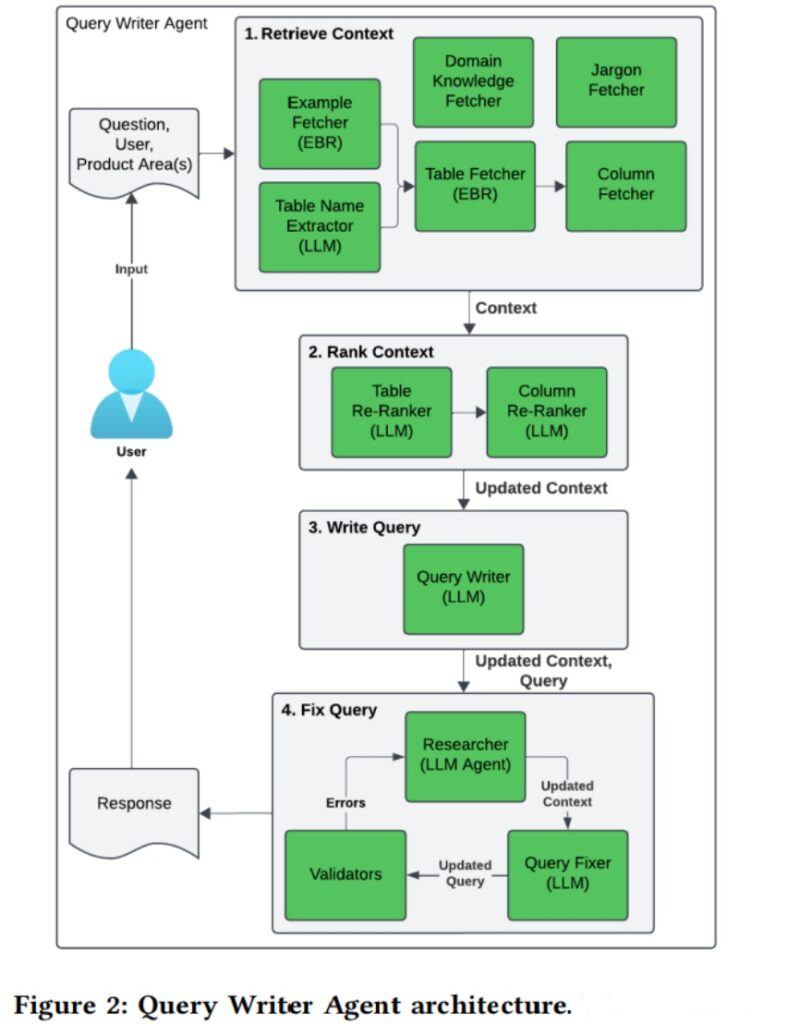
Chen et al. (2025) Figure 2. Text-to-SQL for Enterprise Data Analytics.
https://arxiv.org/abs/2507.14372
Lastly, in Figure 3, we see the user interface and high-level architecture for the chatbot type experience the team developed. Using a “Classifier”, the chatbot is able to define the user’s intent, and route the prompt to the appropriate agent.
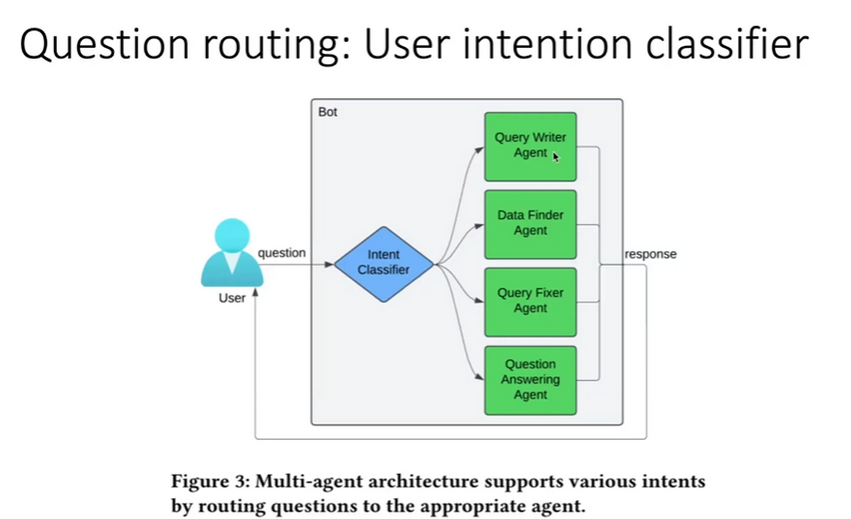
Chen et al. (2025) Figure 3. Text-to-SQL for Enterprise Data Analytics. https://arxiv.org/abs/2507.14372
Evaluation: Measuring Quality in Real Enterprise Conditions
To gauge the success of the results, Chen et al. (2025) used the following performance metrics and criteria:
- 133 benchmark questions across 10 product domains
- Multiple valid SQL answers per question
- Human judges and LLM judges
- A 1–5 scoring system, where 4–5 = acceptable or perfect
Key Takeaways
-
Data organization matters more than the model
- Clustering, metadata, table popularity, and historical queries are as important as model choice.
-
Agentic architecture dramatically boosts performance
- A multi-stage workflow elevates accuracy by 20%-50%.
-
Multi-agent feedback loops reduce hallucinations
- Retrieve → Rank → Write → Fix patterns are essential for correctness.
Final Thoughts
The research from Chen et al. (2025), demonstrates what it takes to operationalize text-to-SQL in large enterprises. It also reveals an important truth about enterprise AI:
If an AI system isn’t working well, the problem may not be the LLM, it may be the data and the context you’re feeding it.
Achieving reliable results requires far more than pointing an LLM at a database. It demands carefully structured context, well-organized data, knowledge graphs that encode enterprise semantics, and agentic workflows designed to retrieve, rank, write, and iteratively fix SQL. In the end, LLMs will not replace enterprise data architecture, they will amplify it. Most importantly, it is the teams that invest in organizing their data, designing agentic systems, and creating user-centric interfaces who will be the ones who unlock the true potential of Gen AI for analytics.
Until next time!
References
Chen, A., Bundele, M., Ahlawat, G., Stetz, P., Wang, Z., Fei, Q., Jung, D., Chu, A., Jayaraman, B., Panth, A., Arora, Y., Jain, S., Varma, R., Ilin, A., Melnychuk, I., Chueh, C., Sil, J., & Wang, X. (2025, July 18). Text-to-SQL for Enterprise Data Analytics. arXiv. https://doi.org/10.48550/arXiv.2507.14372